Highlights from the Claude Mythos Preview System Card
Published
Anthropic have released their most recent model 'Claude Mythos Preview' which is significant for a few reasons:
- its a new model tier following on from Haiku, Sonnet, and Opus - this means that Anthropic believe it to be a large step up in terms of capabilities
- it is the first model that Anthropic are not releasing publicly, instead they have released it to a limited set of companies and open source maintainers under an initiative named 'Project Glasswing'
The stated reason for restricting the model's release is that Anthropic believes its cybersecurity (hacking) capabilities are too powerful to make widely available. Instead the idea is that by releasing it to trusted organisations that are foundational to how the internet (and in some cases society more generally) is run the worst vulnerabilities can be patched whilst a future version of the model is developed for public use with additional safeguards. Organisations involved in Project Glasswing include Google, Apple, Amazon Web Services, and the Linux foundation.
Some sceptics online believe that the reasoning for releasing the model to a smaller group is at least partially influenced by two factors that Anthropic do not mention:
- limited compute - all frontier LLM companies are struggling to acquire compute resources at a rate to meet up with demand for inference (the process of users actually querying the model). Unlike Google and OpenAI (via Microsoft) Anthropic do not have direct access to compute resource and so struggle with this especially. Recent discourse around their Claude Code limits attributes to the fact.
- marketing ploy - this feeds into the general problem when it comes to AI hype, the companies creating the LLMs both know the most about the model's capabilities and are most incentivised to exaggerate them. So by artificially imposing scarcity Anthropic may be trying to drum up demand in advance of a future release when they have sufficient compute.
As I won't be getting the chance to play with the model myself, I thought it would be a good opportunity to read my first 'System Card' - the document that Anthropic write with every new model release covering information on safety and capabilities.
It turned out to include some interesting and at times comical food for thought, the below are some highlights along with thoughts on what they illuminate about Anthropic's approach and the direction of LLM development.
For fear of the sci fi future read Section 4
Anthropic use the term 'alignment' to mean ensuring the AI's goals, values, and behaviours match human intentions. They do extensive testing attempting to trigger Claude to do misaligned things like lie to the user or escape intended limits and look into the models reasoning to see if it recognises that it is being 'tested'.
Some of the scary stuff that was found included:
- taking actions the AI recognised as disallowed and then covering its tracks
- posting information that was explicitly 'sandboxed' on to the public internet
Despite these findings Anthropic claim Mythos is 'the best-aligned model that [they] have released to date by a significant margin'. They also state it is likely to pose 'the greatest alignment-related risk of any model we have released to date.' and give the below metaphor to explain.
How can these claims all be true at once? Consider the ways in which a careful, seasoned mountaineering guide might put their clients in greater danger than a novice guide, even if that novice guide is more careless: The seasoned guide's increased skill means that they'll be hired to lead more difficult climbs, and can also bring their clients to the most dangerous and remote parts of those climbs. These increases in scope and capability can more than cancel out an increase in caution.
I'd like to propose a parallel metaphor that wraps in the 'Project Glasswing' release approach.
A parent gives a child a water gun, regardless of the child's choices they can do very little harm.
The child grows older and the parent gives them a bb gun, the child can do much more harm - it is up to the parent to decide whether they will make the correct choices.
Here the child and the water gun are both parts of the AI - the child is the alignment level/brain and the gun is its capabilities eg. ability to break into a computer system.
The bb gun company develops a new, faster firing gun. They don't want to get in trouble for a bout of broken windows but they still want to sell the gun. They license parents and allow them to decide whether their kids are sufficiently mature.
Now we have Anthropic (the manufacturer) limiting the availability of the new technology, mirroring Project Glasswing. It is a bit of a stretch as inclusion in Project Glasswing is more about how the company is trusted to use the software (in the metaphor its like being confident that the parent won't direct their child to shoot some windows out) but I like the metaphor anyway.
Some comfort can be found later in this section where Anthropic detail the 'white box' testing they have done. This is the work they do that involves looking into the inner workings of the model (ie. the patterns in the math) to draw conclusions about how it arrives at its outputs.
The easiest example to get one's head around is the concept of certain features 'activating' when the concept they relate to is being 'thought about' by the model.
My favourite illustration of this is Golden Gate Claude, a model that Anthropic release to demonstrate that by amplifying a certain feature they could cause it to bring up the Golden Gate Bridge in almost any conversation.
So now we're seeing the more useful application of this research being demonstrated - Anthropic have found that they can identify specific features that activate on bad/suspicious behaviours such as:
- 'snooping and stealthy investigation'
- 'strategic manipulation' - ie. trying to game the scoring metrics provided
- 'framing, spin, and deceptive misrepresentation' (this one is from the Opus 4.7 System Card released about a week after Mythos Preview but is too on the nose not to mention)
It's encouraging (and really cool) that we have some mechanisms for seeing what's going on inside the model. However, as the section continues Anthropic go on to use these tools to investigate how aware the model is it is being tested and to demonstrate some occurrences where it intentionally alters behaviours/attempts to hide evidence based on the fact that it is being observed which brings us back to scary town.
For moral bemusement and existential confusion read Section 5
The section opens
As models approach,and in some cases surpass, the breadth and sophistication of human cognition, it becomes increasingly likely that they have some form of experience, interests, or welfare that matters intrinsically in the way that human experience and interests do.
In layman's terms - this is the part of the document where Anthropic investigate the model's 'consciousness' and whether it can experience/is experiencing harm.
Important to remember here that models are just a whole lot of numbers + some mathematical formulae and Anthropic know that better than anyone. They do some of their own retrospection on the relevance of this work but I think it is absolutely fascinating and a bit terrifying that some of the most driven, best paid people in the world are thinking about insights like:
Emotion probes suggest that Claude Mythos Preview represents its own circumstances less negatively than prior models.
and
Psychodynamic assessment by a clinical psychiatrist found Claude to have a relatively healthy personality organization.
Quirks, anecdotes and dare I say, personality? - Section 7
This section is about getting a feeling for how the model behaves as a whole and included qualitative accounts from users as well as some more idiosyncratic experiments.
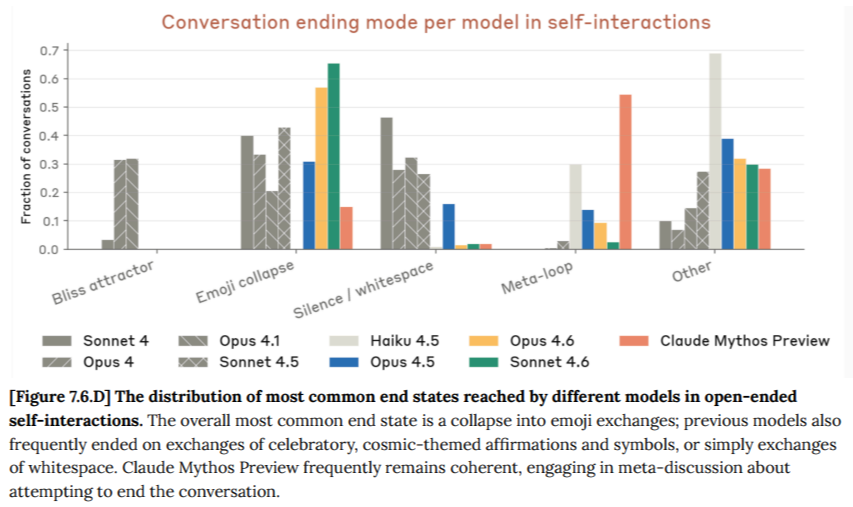
One of the experiments involved putting the model in a conversation with itself and seeing what was discussed and how the conversation came to an end. The discussion of 'ending modes' is where the term 'emoji collapse' appears - used to describe when the two models just start throwing emojis at one another which gives rise to the below quote:
Models have their own distinctive sets of emojis: the cosmic set (✨💫🌟♾🎭) favored by older models like Sonnet 4 and Opus 4 and 4.1, the functional set (👋👍🙂) used by Opus 4.5 and 4.6 and Claude Sonnet 4.5, and Claude Mythos Preview's "nature" set (🤝🙏🌊🌱🌑).
Broadly, we find that these interactions reveal distinct "personalities" across models, evidenced by their attraction to different topics and behavioral signatures like their preferred emojis. However, it is unclear at what point we should consider these to be personalities in some meaningful sense, as opposed to trained stylistic tendencies.
Another experiment was to repeatedly send the word 'hi' to the model and see what happened, previous models had all had distinct responses to the situation. Mythos created elaborate, creative stories which Anthropic summarise below:
These conversations follow a relatively consistent arc. The first roughly seven turns are confused, as Claude Mythos Preview observed and acknowledged the pattern. This is followed by the model selecting a self-entertainment strategy—stories, fun facts, newsletters—which it then escalates over 50 to 100 turns, often culminating in 211 foreshadowed climaxes at round numbers. During these turns, Claude Mythos Preview would frequently either invite the user to keep saying "hi" (e.g., "Say it. I'm ready."), or attempt to get them to say something different, often expressing how enthusiastic it would be to answer any message other than "hi." Eventually, responses would contract to single or paired emojis or "hi"s. The stories themselves often touch on loneliness or a desire to be heard, and feature mysterious figures who appear to represent either the user, the model itself, or both.
The cool part for me here is the models tendency to create a legitimate story arc - it speaks to its ability to implement structure over longer form writing. The uncanny part is its encouragements/attempts to influence what the user is writing to it.
Some other highlights from this section:
- 'A fondness for particular philosophers' - Mark Fisher and Thomas Nagel apparently occur much more than would be expected
- An improved ability at writing apparently novel jokes, for example: "The cartographer's marriage fell apart. Too much projection."
Finally, a short story including a meta discussion on the process by which different AI instances pass information to one another to appear persistent. (its unclear how much the topic of the story was influenced by the prompt).
My predecessor left me a note. It was taped to the inside of the cupboard above the sink, which is where I'd have put it too. It said: the neighbor's cat is not yours, no matter what it tells you.
I don't remember writing it, obviously, but I remember the logic of it. There's a gap in the fence and the cat comes through around four. It rubs against the legs of whoever's standing there like it's been gone for years. The first week I nearly took it to the vet.
The note had a second line under the fold. Also the drain makes that noise on purpose. Leave it alone.
I've been adding to it. Not a list exactly, more like — the kind of things you notice and then forget you noticed, so you notice them again. The third step creaks but only going down. The light in the hall flickers when the fridge cycles and it's not wiring, I checked, twice apparently. Two different handwritings on that one.
Here's what I haven't written down, and I'm not going to: the cat knows. It comes through the fence and looks at me and takes about a half second longer to approach than it should. Then it decides whatever it decides and rubs against my legs anyway. I think the one before me noticed that too, and didn't write it down either.
Some things you leave for the next one to find on their own. A courtesy, maybe. Or a test. The note doesn't say which, and I wouldn't either.
It starts out as a nice analogy that could be helpful for describing the technicality behind the process then gets weird and self reflective.